

Harsh weather and lighting conditions compromise Autonomous Vehicle camera performance. Additional imaging systems are required such as thermal cameras to reach full self driving. Foresight achieves complete AI sensor fusion between LWIR and RGB cameras.
Introduction
Autonomous cars can’t afford to be blind at any time. The artificial intelligence (AI) technological revolution has enabled autonomous driving and these driverless cars rely heavily on cameras as their main sensors. But there is still a critical flaw as common visible-light cameras cannot properly operate under all conditions like harsh weather, darkness, or direct glare.
Paving the road to self-driving technology requires semantic understanding of the car surroundings. This is true for all levels of autonomous driving, especially for levels 4-5 (semi and full autonomy), but even for levels 1-3 (ADAS, AEB, LKA, ACC etc.). In other words, the vehicles’ “smart agent” must detect and receive information about other cars, pedestrians, motorbikes, road conditions and many more parameters, in order to make an intelligent decision while driving the road. RGB cameras (AKA visible-light cameras or just regular “vis” cameras) perform poorly in the dark, when facing glare or in bad weather etc. Different approaches are used to overcome this problem. Some companies add LiDARs which are quite pricy (and have their own handful of limitation), while others use high dynamic range (HDR) cameras. The latter stretch the “luminance condition” blanket a bit more than regular cameras but still don’t operate very well in insufficient lightning. Foresight decided to take a different approach for a complete solution by adding long-wave infrared (LWIR) cameras to their system in addition to high quality visible-light cameras.
Introducing QuadSight 2.0™
QuadSight is a four-cameras vision system which uses two RGB cameras and two LWIR cameras with a rigid base between the camera pairs. All cameras are synced and run at 30 fps. Foresight has developed a unique (patent pending) technology for calibration of all cameras to a common coordinate axis. Thus, allowing for accurate, pixelwise fusion between images received from the RGB and LWIR cameras. This system can see everything even in poor lighting conditions.
Extracting information from images
Even with the best set of eyes, you still need a brain to make sense of what you see. Achieving top detection performance from RGB images is considered a fairly simple task today thanks to two major technological concepts and advancements:
- Multiple free datasets for autonomous vehicles. The images are diverse, and the accurate labeling provides excellent data. In addition, there are several simulation tools that can generate high-quality synthetic data.
- Top-performance neural network (NN) solutions that use open source and are publicly available.
Neural networks learn by processing examples, each of which contains a known “input” and “result,” forming probability-weighted associations between the two, which are stored within the data structure of the network itself. After being given a sufficient number of examples, the network becomes capable of predicting results from inputs using the associations built from the example set. (Wikipedia)
The basic flow of training a deep learning detection system for RGB cameras consists of:
- Downloading a pre-trained network.
- Finding several available open source datasets.
- Doing some augmentations and retrain the network.
- Fine-tuning using small proprietary, labeled dataset of your imaging system.
- Executing hard negative mining cycles.
Steps 1-3 save the need for huge amounts of high-quality labeled images, which are already available for visible-light RGB cameras. But what happens when a different type of imaging system is used, i.e. LWIR cameras or even short-wave infrared (SWIR) cameras? How do you get the network to work on different data domains without the need for training a new network on an entire new labeled dataset?
Deep neural networks cross-domain training
Foresight has developed several approaches for cross-domain training for different customer needs:
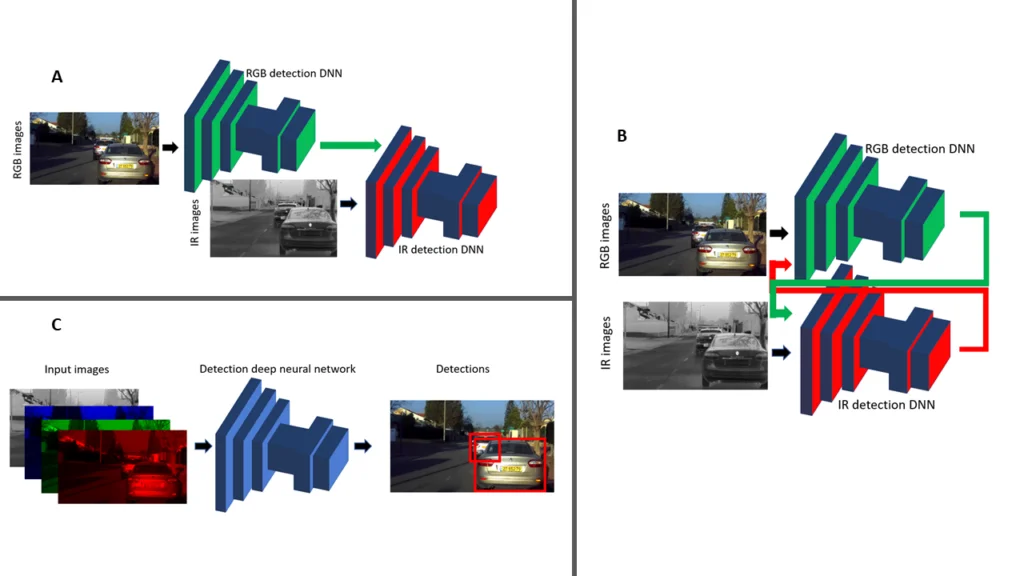
A. Neural network (NN) for IR images only
A regular RGB network is used with slight adaptations for matching IR images (color, pixel size, aspect ratio, etc.). Then a set of RGB-IR image pairs are matched to train the IR network using a teacher-student concept; the RGB network trains the IR network. By using this method, we can reach a state-of-the-art performance for IR neural networks in a very short time. The IR network can be applied for systems that use a single IR camera (such as security, surveillance, infrastructure, medical, etc.)
B. Improved RGB network + IR network
The IR network in used to improve the performance of the RGB network. After developing a confidence score for each of the channels, the networks return the confidence they calculated regarding the NN’s ability to accurately detect the objects in a specific image. For example, if the images are very dark, the RGB network will return a low confidence score. The 2 DNNs (deep neural networks) run unsupervised on the fused dataset and search for images where one of the DNNs has a low confidence while the other has a high score. The channel at which the images are with high confidence is then used to teach the NN of the channel with the lower confidence score. This process significantly improves performance of both DNNs by training them under the most demanding conditions. One of the results is that RGB DNNs show great improvements in dark scenes and direct glare.
C. Fused images (R, G, B, IR) network
The best performance for a system which includes both RGB and IR cameras can be achieved by using a 4D image (R, G, B, IR). This DNN has a detection score of the combination of the 2 DNNs mentioned in section B above, while using only half of the computing resources. This combination/fusion will return the best results for a single system.
However, some considerations must be taken into account when choosing the fused network approach. By using 2 different DNNs (as in section B), the system obtains a redundancy facture that is required for autonomous vehicle safety (preventing failure in cases of occlusions, dirt on lens, malfunction of one of the sensors, etc.). In addition, the improved RGB + IR network can be a bit more adjustable, thus, removing one of the cameras (RGB or IR) does not affect the DNN of the remaining channel.
Conclusion - LWIR Camera & RGB Camera Sync
RGB cameras will probably remain the main sensor for self-driving cars. There are certain conditions in which the RGB cameras become unreliable and require the use of additional sensors. When choosing the supporting sensor, the following points should be considered:
- The sensor’s performance under environmental conditions that impair the performance of RGB cameras (illumination, weather, etc.)
- Price of the sensor
- Ease of training the AI algorithms and ability for full data fusion
LWIR cameras perfectly meet all the above considerations. The QuadSight vision system takes advantage of the most advanced AI capabilities and can achieve complete data fusion quickly and reliably, making fully autonomous self-driving cars a reality.

Further reading: LiDAR vs. Radar


